Managing Multiple Databases in Neo4j
|
Important - page not maintained
This page is no longer being maintained and its content may be out of date. For the latest guidance, please visit the Neo4j Operations Manual . |
In this guide, we will walk through how to manage multiple database within the Neo4j DBMS.
Please have Neo4j (version 4.0 or later) downloaded and installed. It helps to have read the section on graph databases.
Beginner
In Neo4j (v4.0+), we can create and use more than one active database at the same time. This works in standalone and causal cluster scenarios and allows us to maintain multiple, separate graphs in one installation.
When we create a database, Neo4j will initially create a system database and a default database.
The system database is named system and contains the overall information that applies across databases - managing administration of individual databases (stopping and starting) and maintaining user privileges (security roles and privileges).
The default database is named neo4j (can be changed) and is where we can store and query data in a graph and integrate with other applications and tools.
We can also create additional databases, as needed, to store other graphs and different data that may be unrelated to any of our other databases.
System setup
If you haven’t already, download Neo4j.
We will need to have a database running and open Neo4j Browser to walk through this guide. If you are unsure how to create and start a database, step-by-step instructions for doing so in Neo4j Desktop are provided in this guide.
Reviewing the initial databases
As mentioned earlier, when Neo4j is installed and an instance created, it will be initiated with two databases - a system database and a default (neo4j) database.
Launching Neo4j Browser will automatically point us to the neo4j default database, shown by the neo4j$ prompt in the command line.
If we want to see the system information (view, create/delete, manage databases), we will need to switch to the system database.
We can do that with the :use command then telling it which database we want.
Command: :use system
Now we can run a command to see the databases created with the instance.
The SHOW DATABASES command will display all databases in our instance (or databases across instances in a cluster) along with address, role, requested and current statuses, any errors, and which database is default.

That looks as we expected. Now let’s add another database to the list.
Creating a new database (Enterprise only)
To add a database to our instance, we can use the CREATE DATABASE command.
We are going to use an example called movieGraph, but you could choose any name for the database.
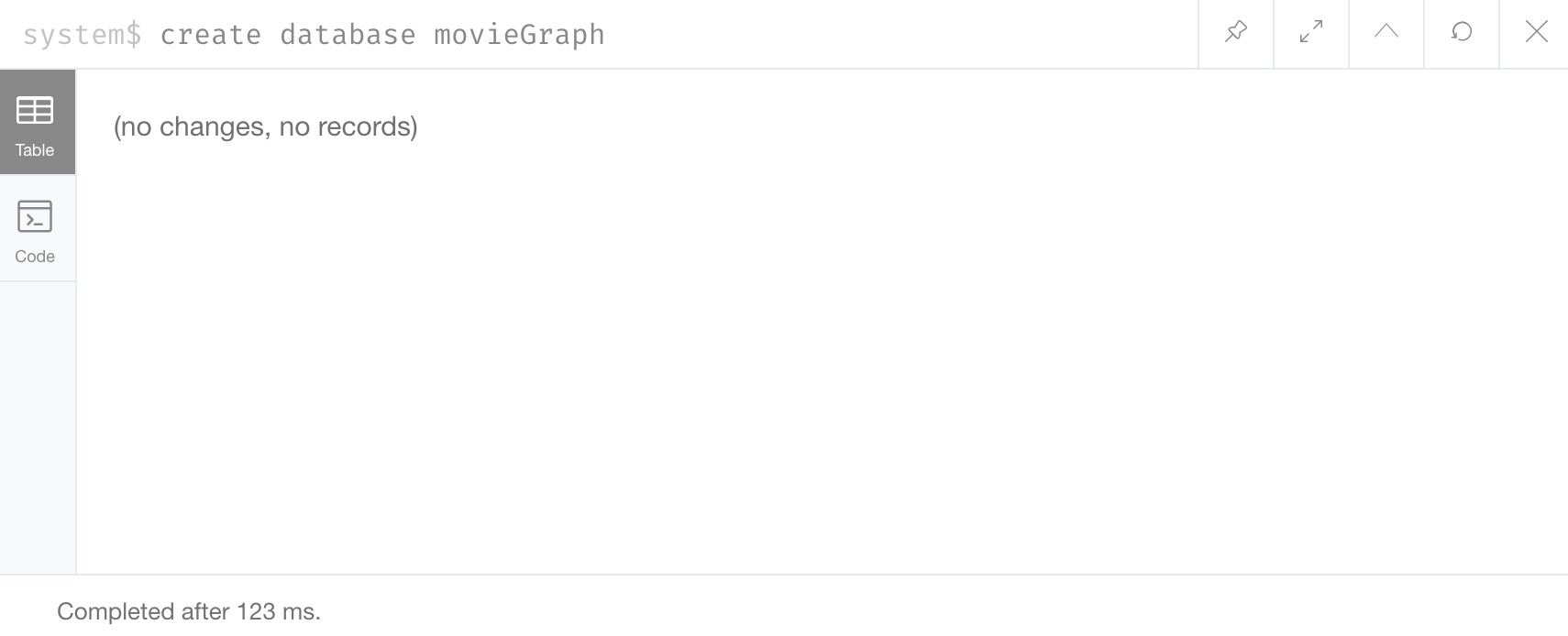
While the result message does not seem convincing that our creation command worked, we can verify by running the SHOW DATABASES command again to see our new database show up in the list!
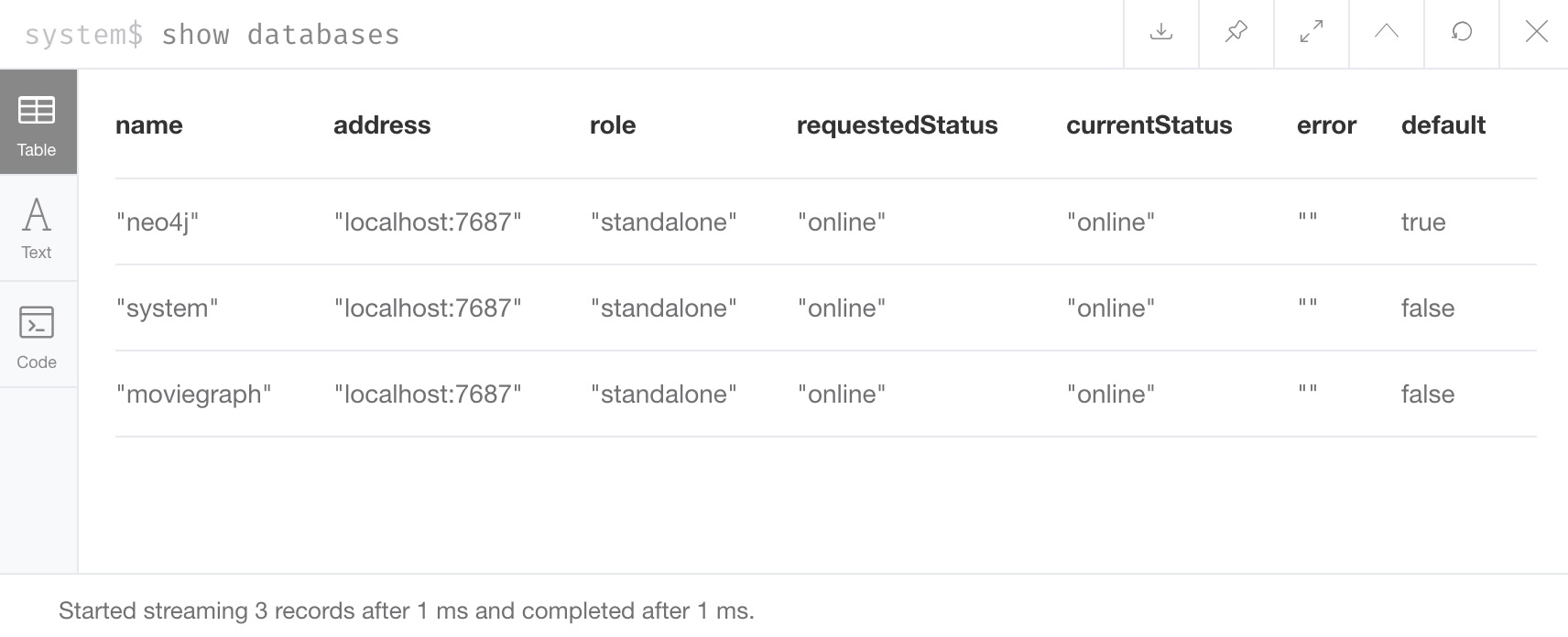
That looks good.
We can switch to our new database to start working with that one specifically (command is :use movieGraph).
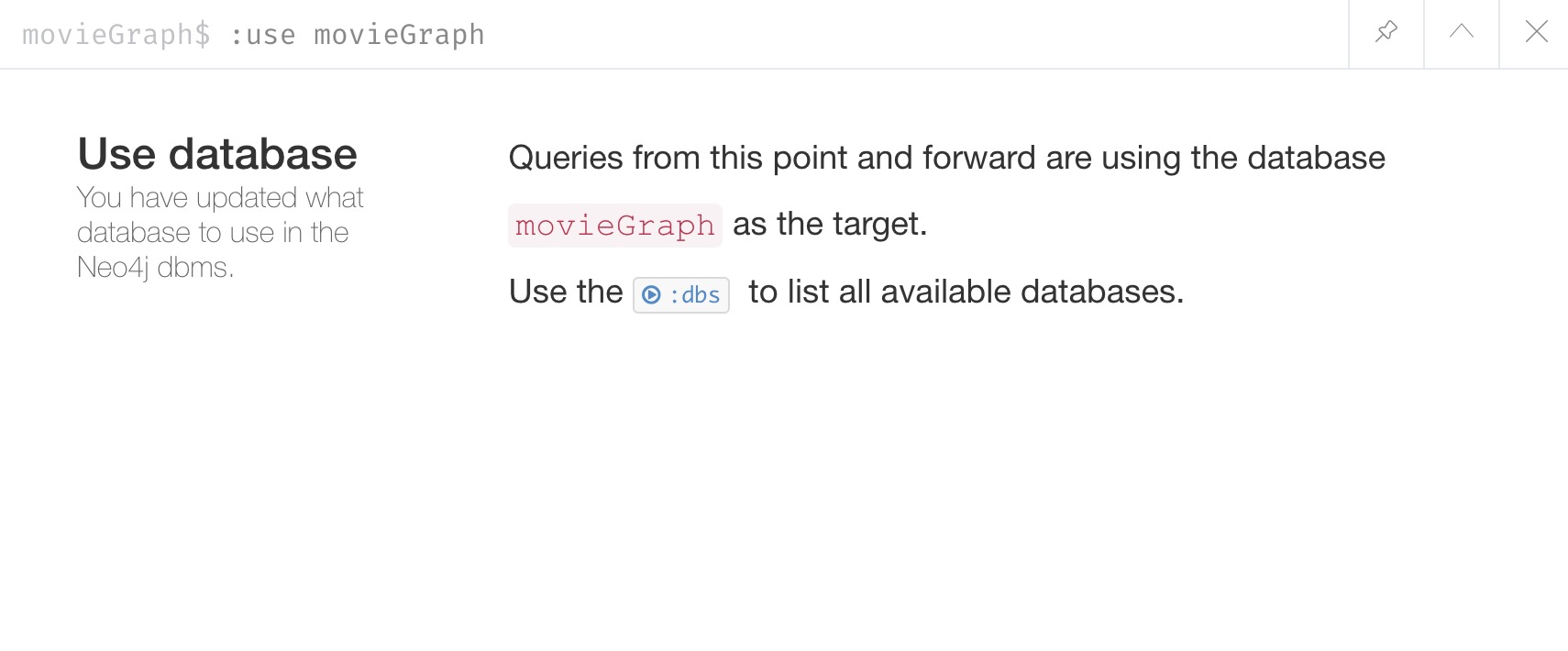
Loading data and working with our movieGraph database
Next, we will load some sample data into our movieGraph database and work with it.
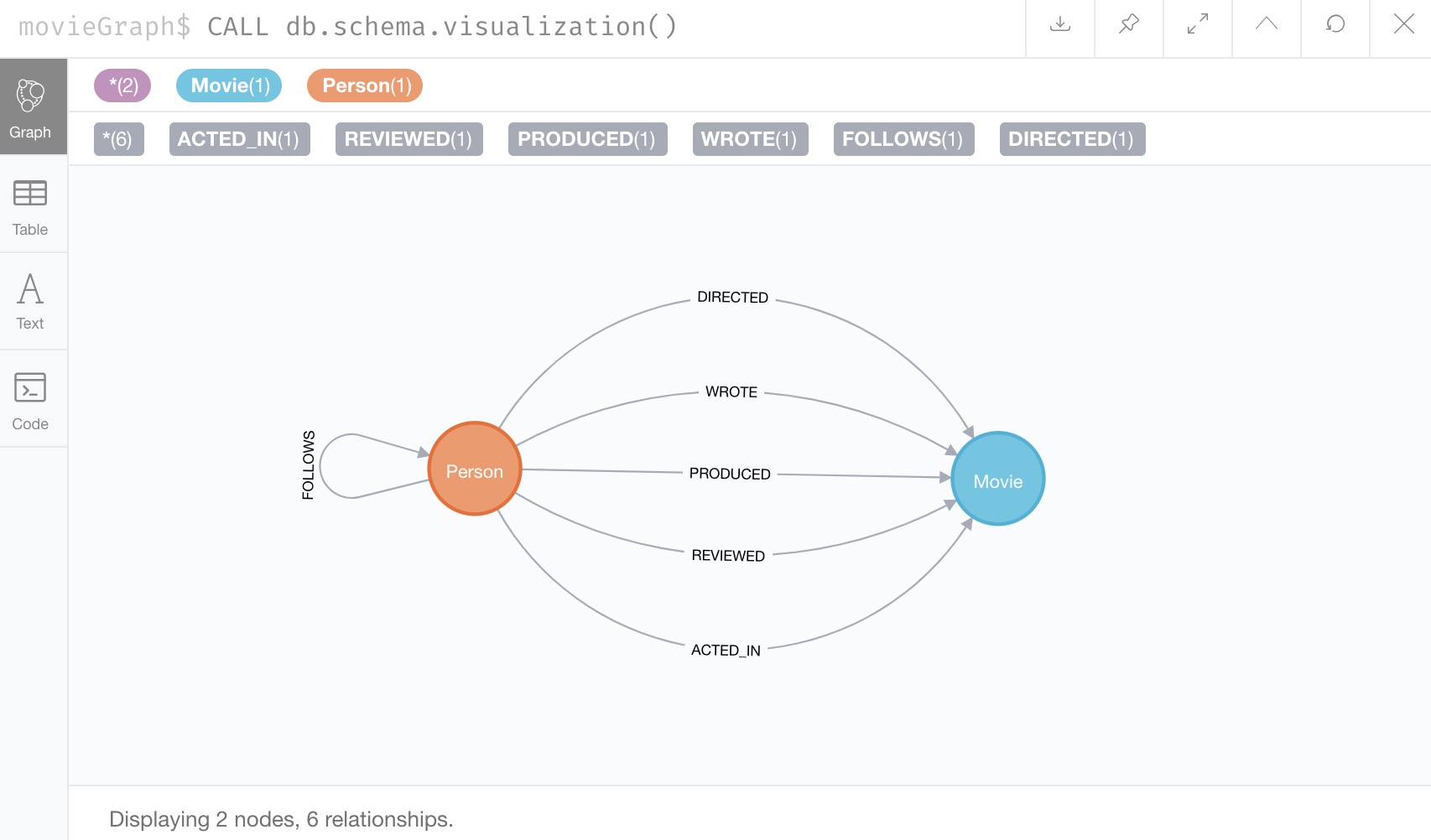
Before we do that, let us verify that our database is truly empty by viewing the schema using the CALL db.schema.visualization() procedure.

No node or relationship data is shown in our results, so the database is empty. Once we add data in a bit, we will see a data model visualization in the results. We can do another quick test by writing a Cypher query to return any nodes and relationships.
Command: MATCH (node)-[rel]-(other) RETURN node, rel, other
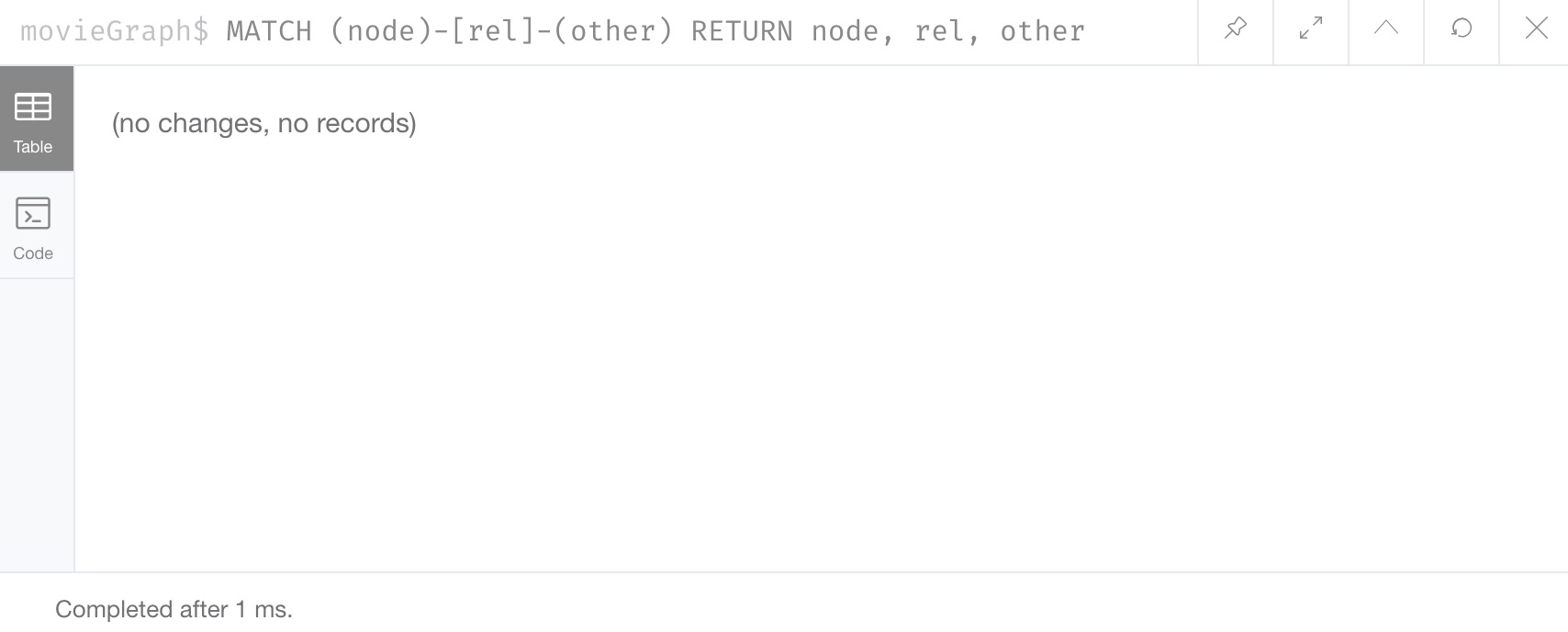
All clear. Now let us add some data.
Load movie data
We will use the small data set for movies that Neo4j users may already be familiar with.
To load, type the command :play movies into the command line and execute it.
A guide will display in the result pane.

We can navigate to the second slide by clicking the arrow on the right side of the pane, and a slide with a long Cypher query should appear.
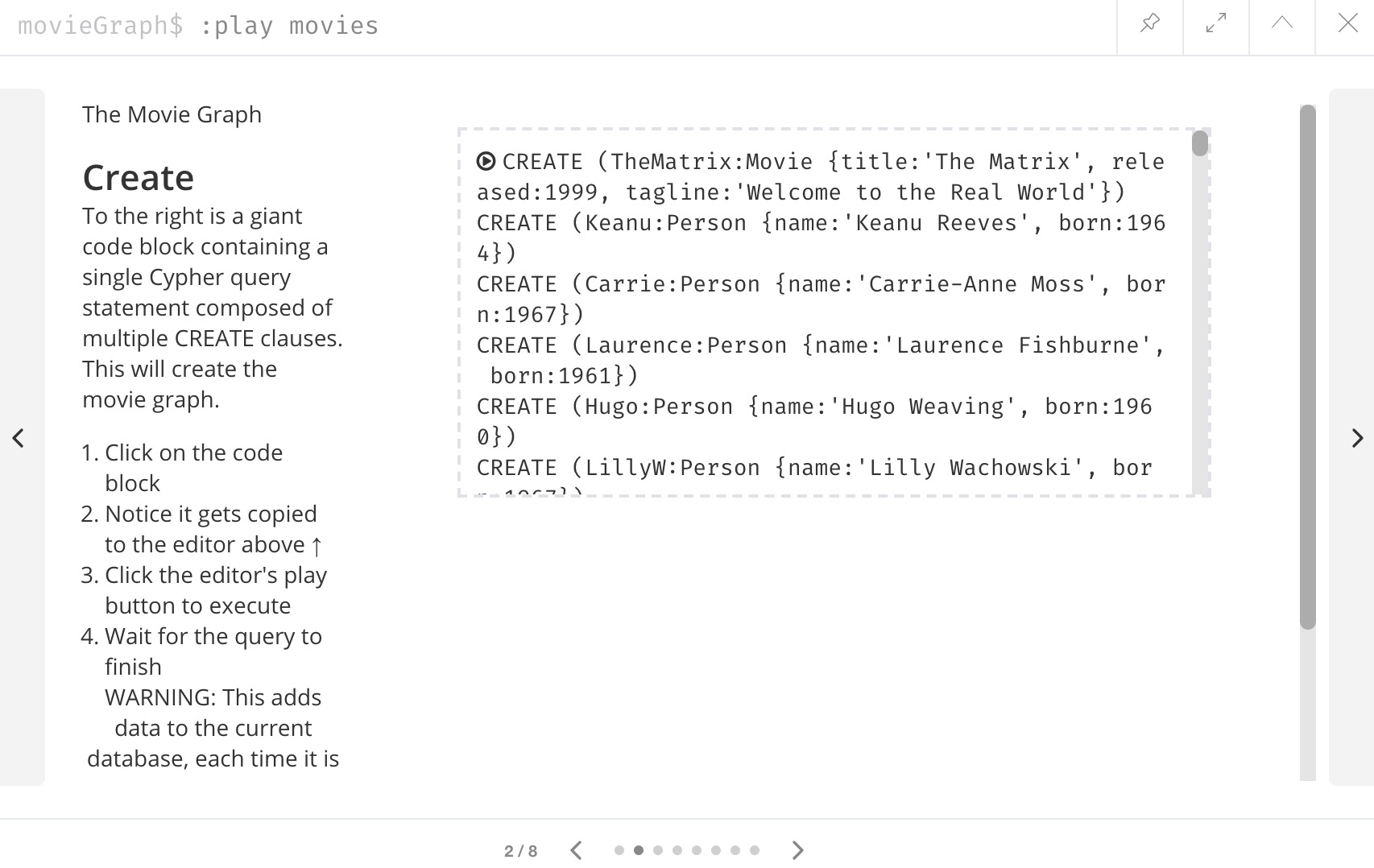
The Cypher query on the right will be outlined with a grey dotted line. We can click that query, and it will copy/paste into the command line. Click to execute the query, which will return some results confirming that data was loaded.
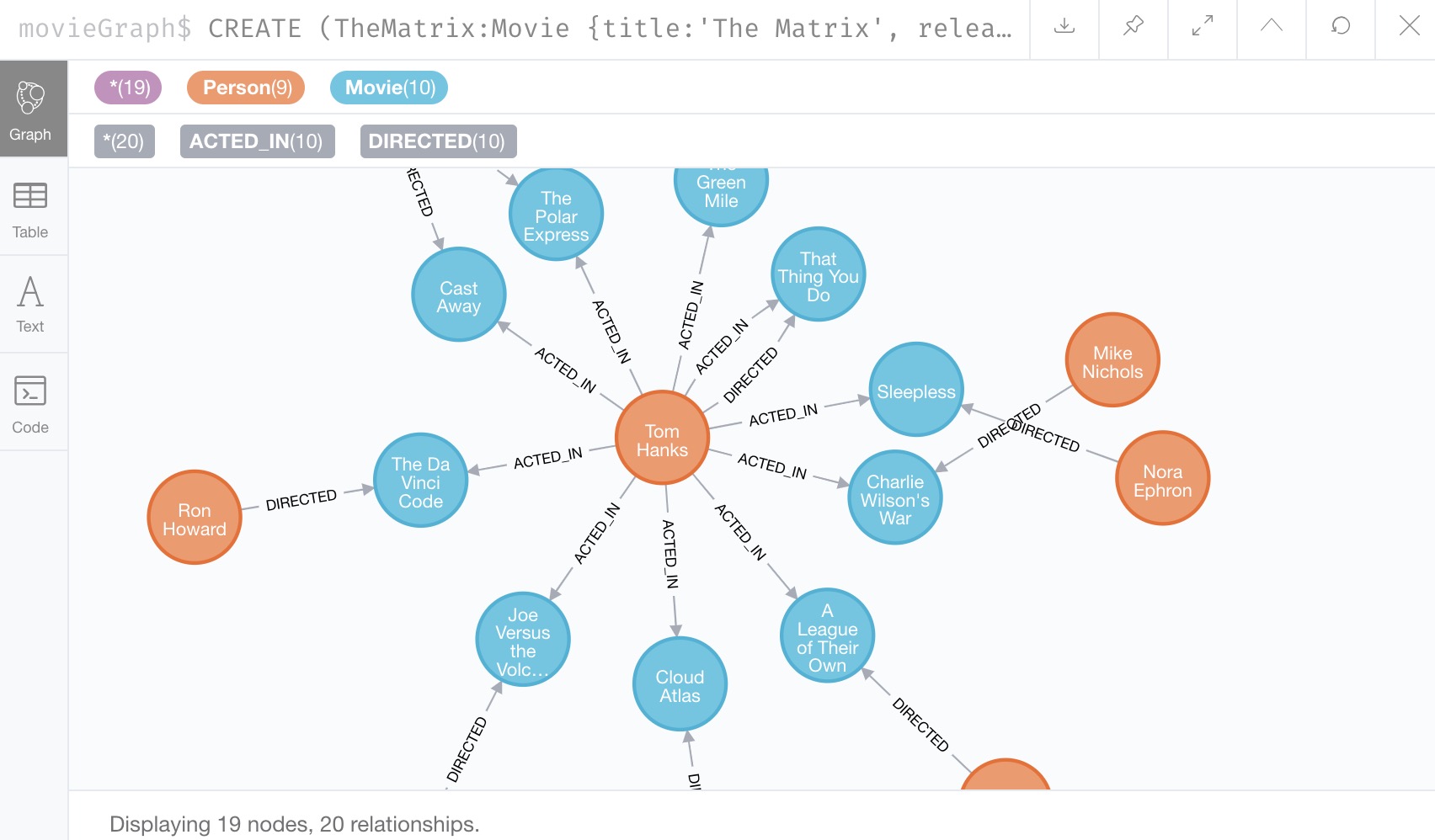
We can also check our schema procedure again to see how data is organized in the database (data model).
Use the command CALL db.schema.visualization() again and execute it to see that we have Person nodes and Movie nodes that are connected by several different kinds of relationships.
We can now run any queries against our movie data that we would like. For instance, using a generic query like the one below below will search for nodes that have any relationships to other nodes.
MATCH (node)-[rel]->(other)
RETURN node, rel, otherThough we can query and work with our movie data, we want to work with the multi-database feature and see that the data in one database is not accessible in the other database. To do that, we need to load some different data in another database.
Loading data and working with our neo4j database
Let us go back to our default neo4j database and load the Northwind retail system data there.
This way, when we look at our databases (movieGraph and neo4j), we will see two completely different sets of data.
The :use neo4j command will switch us to that database and allow us to load there.
To confirm there is no data in this database currently, we can run the CALL db.schema.visualization() procedure against neo4j.

Everything looks clear. We can also run the test query from above, if we want to confirm that way. Now we are ready to add some data.
Loading northwind data
We will use the Browser guide :play northwind that has built-in Cypher queries we can run to load retail suppliers, products, and product categories.

Click the arrow on the right side of the result pane to get to the next slide in the guide, and there will be 3 load statements and 3 indexing statements.
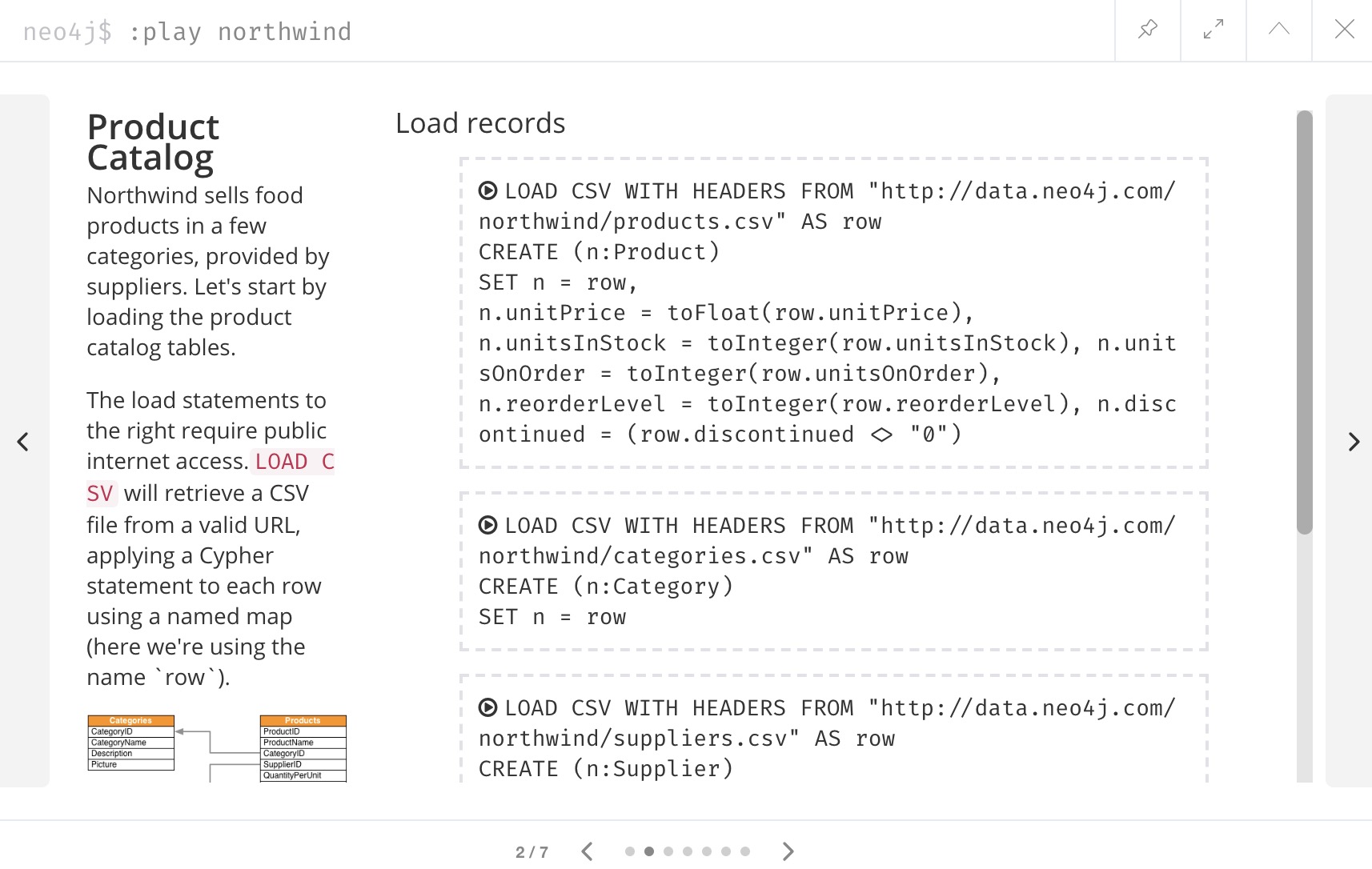
Execute all 6 of those to populate the nodes, then click the right arrow on the guide once more to progress to the next slide. On this slide, we have 2 more statements to find nodes and create relationships between them.
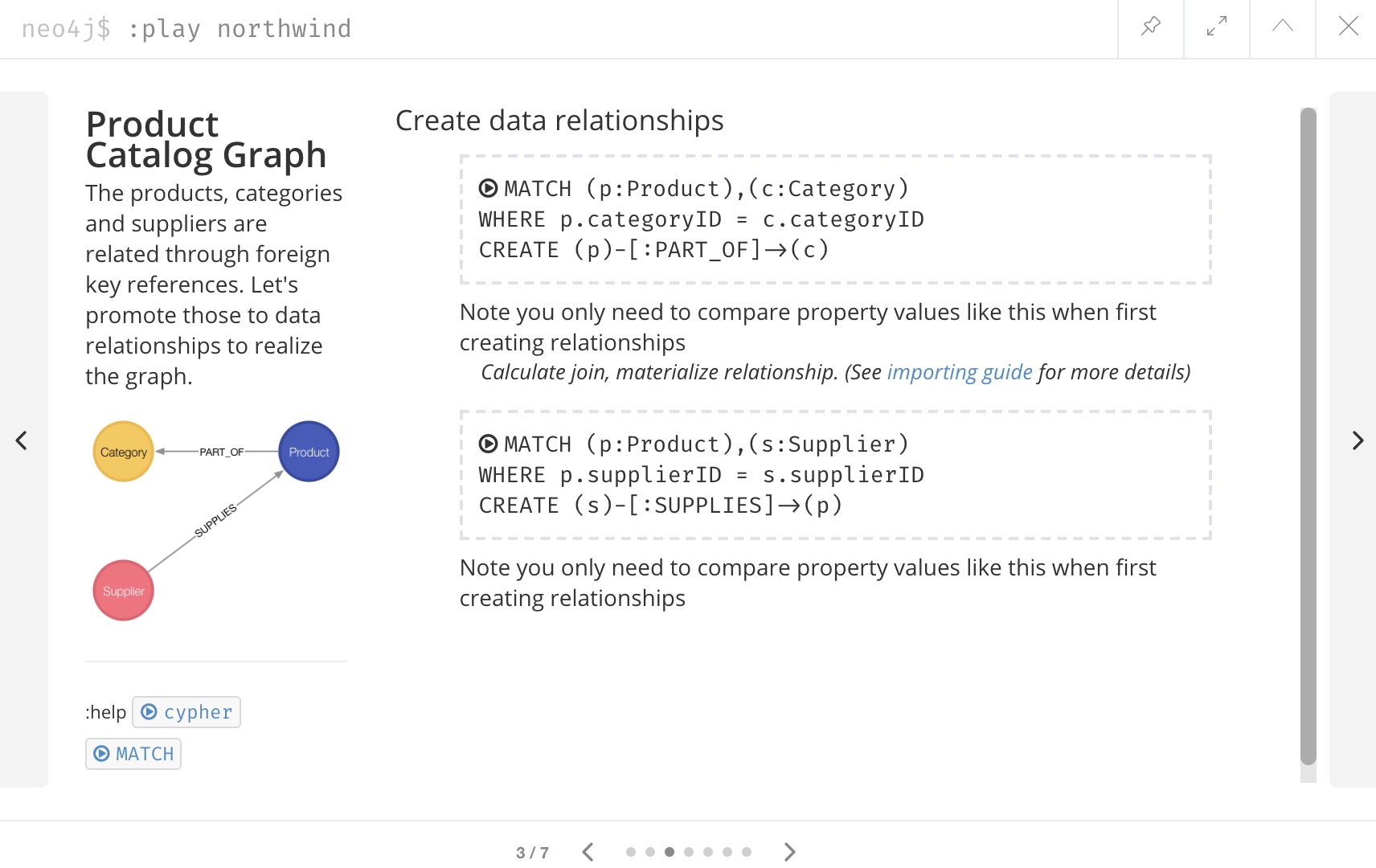
Click and run both statements, then we can check that our data loaded correctly by running the schema procedure again.
We should expect Supplier nodes with a relationship to Product nodes with a relationship to Category nodes.
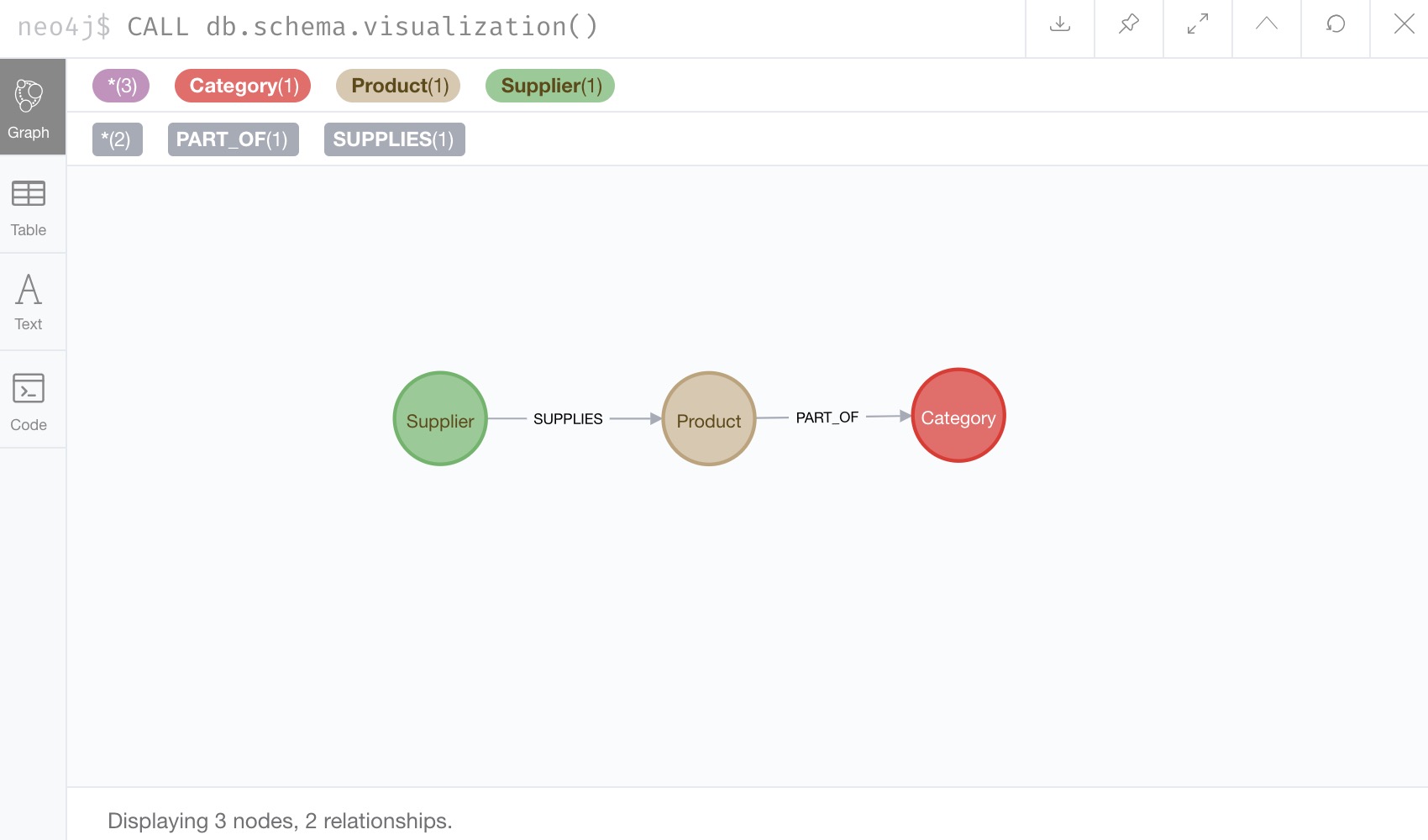
That is how we expected it! We can run our generic test query again to retrieve some of our Northwind data.
MATCH (node)-[rel]->(other)
RETURN node, rel, otherNotice that we do not see any of our movie database entities or relationships in the data model or in our test query.
Those are in our movieGraph database and are completely separate.
If those nodes and relationships existed in this graph, the test query would retrieve them because we do not specify any certain types of nodes and relationships in the search.
We can do one more step to verify Northwind data is not in our movieGraph database either.
Navigating between datasets and databases
Let us switch back to our movieGraph database one more time with the :use movieGraph command.
Next, we run the familiar CALL db.schema.visualization() procedure to pull back our data model.
We see that there is no Northwind data in this graph. That looks good. Our generic test query could be another verification method, as well.
We can continue to operate each of these graphs separately and yet connect to the disparate data sets from the same Neo4j installation without separate instances.
Cleaning out database within same instance
One final administrative difference is how to completely clean out one database without impacting the entire instance with multiple databases. When dealing with a single instance and single database approach, users can delete the entire instance and start fresh. However, with multiple databases, we cannot do that unless we are comfortable losing everything from our other databases in that instance.
The approach is similar to other DBMSs where we can drop and recreate the database, but retain everything else.
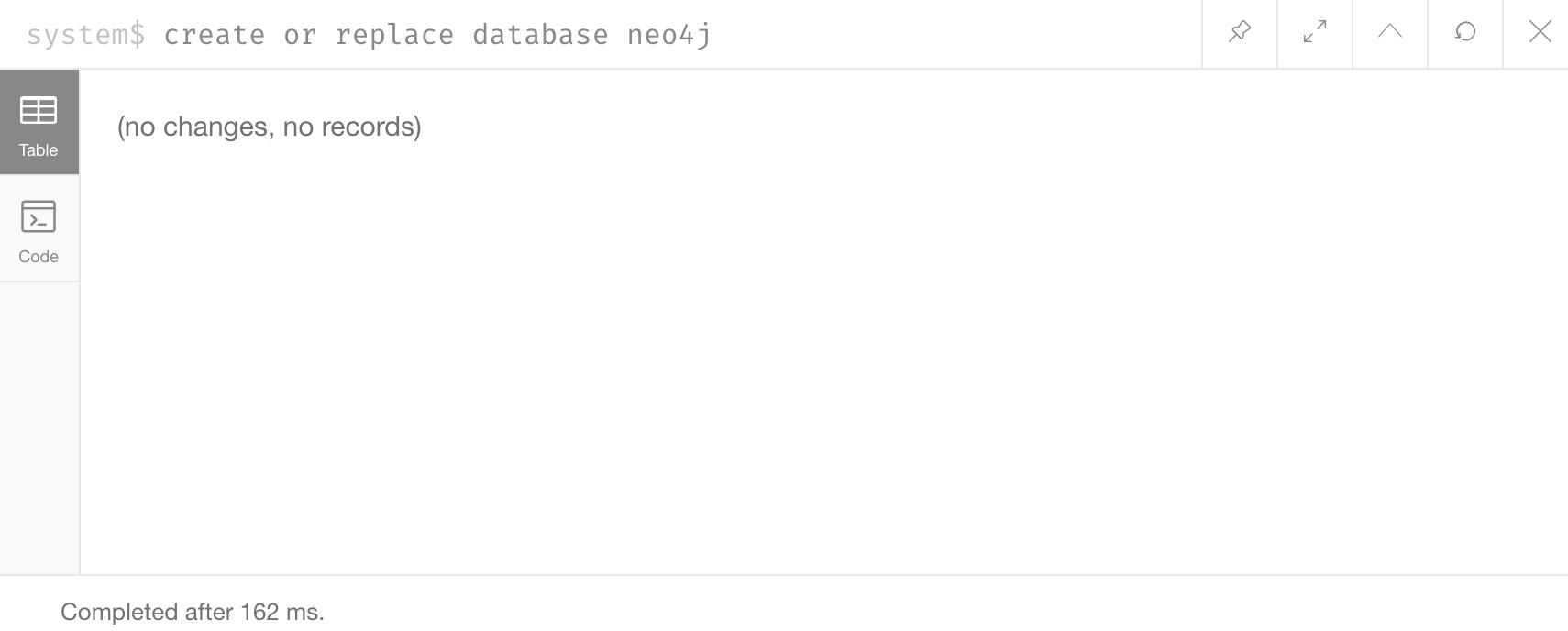
Cypher’s command for this is CREATE OR REPLACE DATABASE <name>.
This will create the database (if it does not already exist) or replace an existing database with a clean one.
For example, when working through these examples, we may alter a load query incorrectly or accidentally add or delete data that we need.
In this case, deleting all the data will not completely wipe indexes or the ghost entities for the data model.
Instead, we can use the CREATE OR REPLACE DATABASE command and start over.
Command: CREATE OR REPLACE DATABASE neo4j