Neo4j Agent Memory
Neo4j Labs · Graph-native memory for AI agents
Your agents forget everything. Fix that.
Graph-native memory for single- and multi-agent systems. Three memory layers — conversations, entities, reasoning — in one graph. Available as a hosted service (zero infra, just an API key) or run against your own Neo4j. Python + TypeScript SDKs that interoperate.
|
Experimental · Community Supported |
Pick your install
| Path | Get started in ~30 seconds |
|---|---|
Hosted service (recommended for new projects) |
|
Self-hosted Neo4j |
|
Get Started · Python SDK · TypeScript SDK · GitHub · PyPI · npm
Three Memory Types, One Graph
Most agent memory systems give you a flat context window or a simple vector store. Neo4j Agent Memory gives your agent three distinct memory layers — all connected in a single knowledge graph.
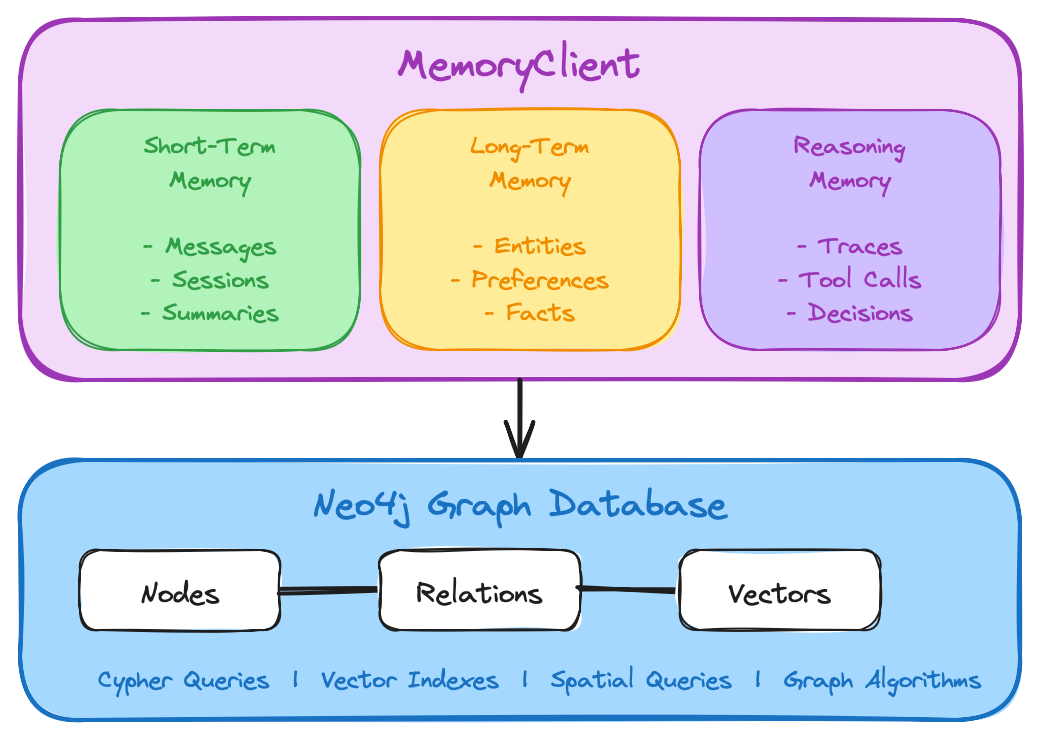
| Memory Type | What It Stores | Key Features |
|---|---|---|
Short-Term |
Conversations & experiences |
Semantic message search, session scoping, metadata filters, LLM-powered summaries |
Long-Term |
Facts, entities & preferences |
POLE+O entity classification, entity deduplication, temporal fact validity, geospatial queries |
Reasoning |
Tool usage & reasoning traces |
Trace similarity search, tool call statistics, message-linked traces, streaming trace recording |
async with MemoryClient(settings) as memory:
# Short-term: store conversations
await memory.short_term.add_message(session_id, "user", "Find Italian restaurants near me")
# Long-term: build a knowledge graph
await memory.long_term.add_entity("La Trattoria", "ORGANIZATION", subtype="COMPANY")
# Reasoning: record how the agent solved problems
trace = await memory.reasoning.start_trace(session_id, task="Restaurant search")
await memory.reasoning.record_tool_call(step.id, "search_api", {"query": "Italian"}, results)
await memory.reasoning.complete_trace(trace.id, outcome="Recommended La Trattoria", success=True)
# Get unified context for LLM prompts
context = await memory.get_context("restaurant recommendation", session_id=session_id)Multi-Agent Ready
Multiple agents — even in different languages — can read and write the same memory graph. Conversations stay private per session; entities, preferences, and facts are shared.
| Capability | How it works |
|---|---|
Shared knowledge graph |
Every agent in the system reads the same |
Per-session isolation |
|
Cross-language by design |
A Python agent (PydanticAI, LangChain, CrewAI, Google ADK, AWS Strands) and a TypeScript agent (Vercel AI SDK, LangChain JS, Mastra, MCP) on the same NAMS endpoint share memory transparently. Both SDKs implement the same NAMS REST contract. |
Multi-tenant scoping |
Pass |
See Cross-Agent Memory Sharing for the conceptual model and NAMS Quickstart for the deployment shape.
What Makes This Different
| Capability | Why It Matters |
|---|---|
Graph-Native, Not Bolted On |
Built on Neo4j from the ground up. Entities, messages, traces, and preferences are all nodes and relationships — not rows in a table or chunks in a vector store. Query across memory types with a single traversal. |
Vector + Graph + Spatial in One |
Semantic similarity search, graph traversal, and geospatial queries all in one database. No separate vector DB, no Redis, no Postgres. Find entities by meaning, by relationship, or by location. |
Multi-Stage Entity Extraction |
Combine spaCy, GLiNER2, GLiREL, and LLM extractors in a configurable pipeline. 8 domain schemas (podcast, news, medical, legal…). Streaming extraction for 100K+ token documents. |
Three Memory Layers, Connected |
Short-term conversations inform long-term entity extraction. Reasoning traces link back to triggering messages. The agent understands what happened, what it knows, and how it solved things. |
Wikipedia Enrichment & Geocoding |
Entities are automatically enriched with Wikipedia descriptions, images, and Wikidata IDs. Location entities get coordinates for geospatial queries. All in the background. |
Framework Agnostic |
Python: LangChain, PydanticAI, LlamaIndex, CrewAI, OpenAI Agents, AWS Strands, Google ADK, Microsoft Agent Framework, AgentCore. TypeScript: Vercel AI SDK, LangChain JS, Mastra, AWS Strands, MCP tools. Or use the client directly. |
Hosted or Self-Hosted |
Use the NAMS hosted service for zero-infra deployments, or run the same SDK against your own Neo4j (Aura, Desktop, Docker) when you need write-Cypher, geospatial, or air-gapped operation. See Bolt vs NAMS. |
Demos
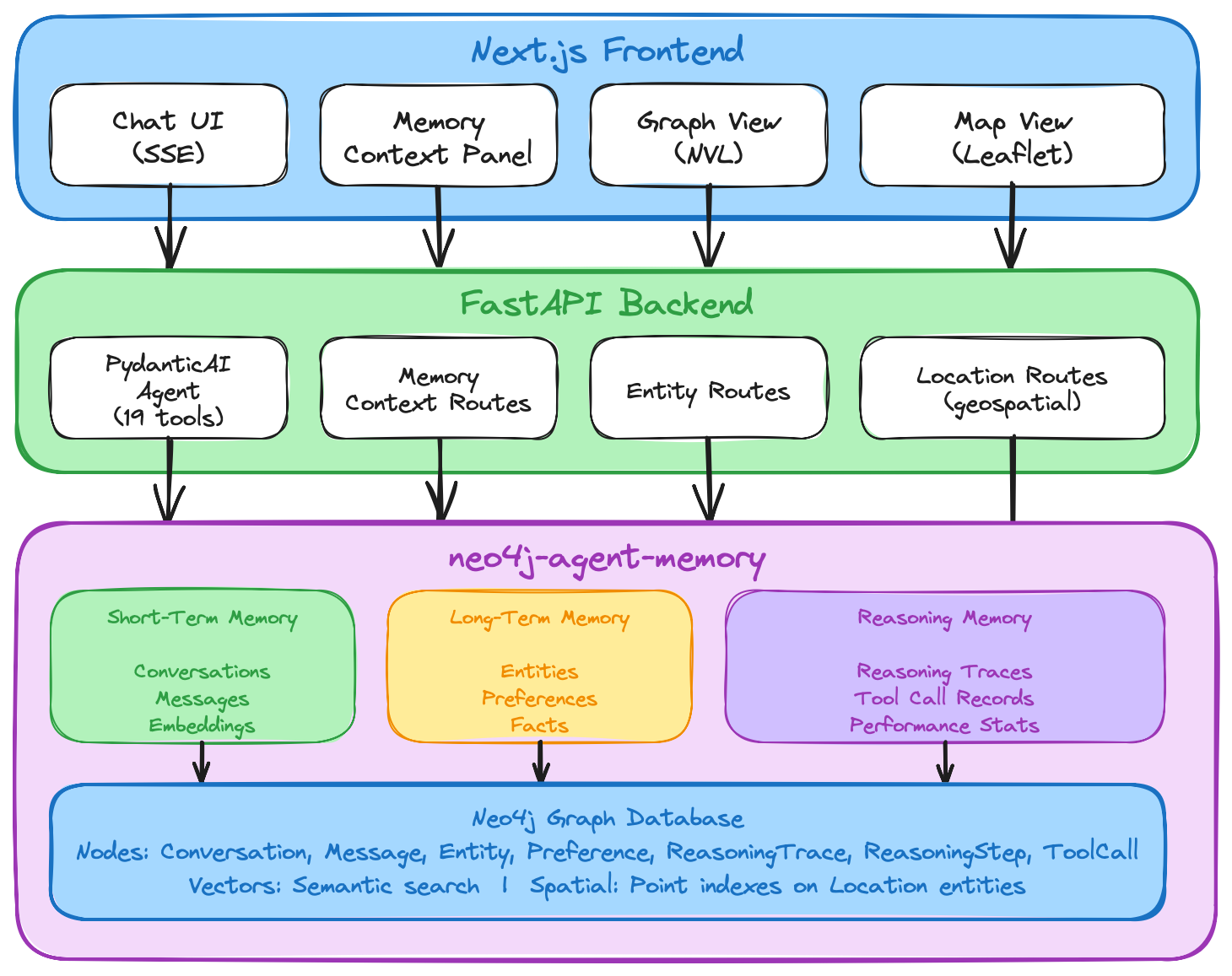
Lenny’s Podcast Memory Explorer (Flagship)
299 podcast episodes transformed into a searchable knowledge graph with a full-stack AI chat agent, interactive graph visualization, geospatial map view, and Wikipedia-enriched entity cards.
| Episodes loaded | Agent tools | Memory types |
|---|---|---|
299 |
19 |
3 |
-
Interactive graph visualization (Neo4j NVL)
-
Geospatial map with marker clusters & heatmaps
-
Wikipedia-enriched entity cards with images
-
SSE streaming with tool call visualization
-
Automatic preference learning from conversation
-
FastAPI + PydanticAI + Next.js + Chakra UI
Full-Stack Chat Agent
A news research assistant that uses all three memory types with an interactive memory graph visualization. Double-click nodes to expand neighbors and explore the knowledge graph.
-
Memory graph visualization with expansion
-
Conversation-scoped graph filtering
-
Dual Neo4j databases (memory + news)
Quick Start
pip install neo4j-agent-memory[openai]import asyncio
from pydantic import SecretStr
from neo4j_agent_memory import MemoryClient, MemorySettings
async def main():
settings = MemorySettings(
neo4j={"uri": "bolt://localhost:7687", "password": SecretStr("password")}
)
async with MemoryClient(settings) as memory:
# Store a conversation
await memory.short_term.add_message("user-123", "user", "I love Italian food!")
# Build knowledge automatically
await memory.long_term.add_preference("food", "Loves Italian cuisine", confidence=0.9)
# Get combined context for your LLM
context = await memory.get_context("restaurant recommendation", session_id="user-123")
print(context)
asyncio.run(main())Entity Extraction Pipeline
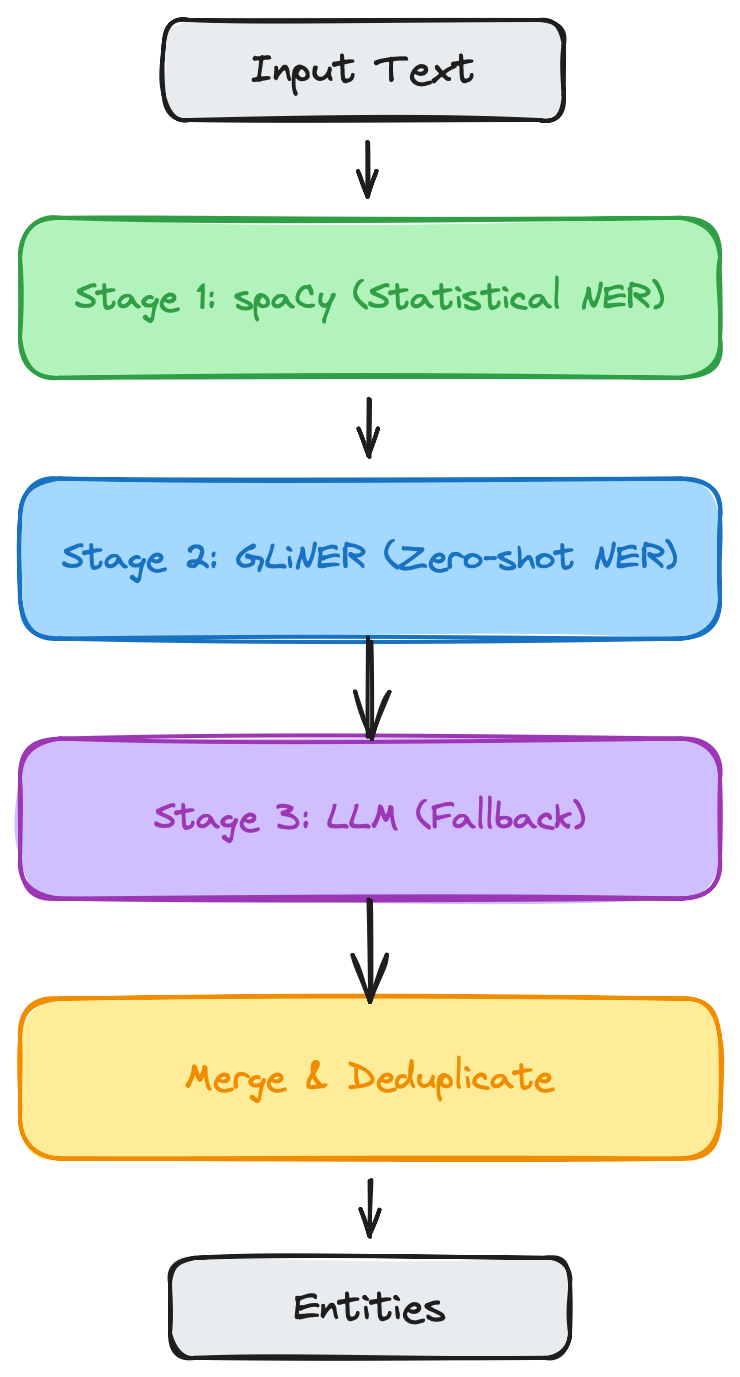
Combine extractors in a configurable pipeline. 5 merge strategies. 8 domain schemas. Streaming extraction for 100K+ token documents.
| Stage | Purpose | Best for |
|---|---|---|
spaCy |
Fast rule-based & statistical NER |
High throughput, no API cost |
GLiNER2 |
Zero-shot NER with domain schemas |
Accuracy without LLM cost |
GLiREL |
Relation extraction between entities |
Graph edge extraction |
LLM fallback |
High-accuracy extraction via API |
Complex or ambiguous text |
Framework Integrations
Python (neo4j-agent-memory)
| Framework | Integration | Guide |
|---|---|---|
LangChain |
Memory & retriever |
|
PydanticAI |
Deps & trace recording |
|
LlamaIndex |
Memory nodes |
|
CrewAI |
Crew memory |
|
OpenAI Agents |
Session memory |
|
AWS Strands |
Agent tools |
|
Google ADK |
MemoryService |
|
Microsoft Agent Framework |
ContextProvider + GDS |
|
AWS AgentCore |
HybridMemoryProvider |
TypeScript (@neo4j-labs/agent-memory)
| Framework | Integration | Guide |
|---|---|---|
Vercel AI SDK |
Middleware (3-tier context injection + auto-persist) |
|
LangChain JS |
|
|
Mastra |
|
|
AWS Strands (JS) |
Session storage + conversation manager |
|
MCP tools |
12 standard tools + dispatcher (Node, Bun, Deno, Workers, Edge) |
Documentation
| Section | Purpose | Start here |
|---|---|---|
Learn by building complete examples |
||
Practical recipes for common tasks |
||
Technical specifications and API docs |
||
Concepts and architecture |
Quick Links
| Guide | Description |
|---|---|
Installation, setup, and your first memory-enabled agent |
|
Deep dive into short-term, long-term, and reasoning memory |
|
Domain schemas, multi-stage pipelines, and custom extractors |
|
Complete configuration options and environment variables |
|
Using with PydanticAI, LangChain, LlamaIndex, and CrewAI |
Requirements
| If you use… | You need… |
|---|---|
NAMS (hosted) |
Python 3.10+ or Node.js 20+. An API key from memory.neo4jlabs.com. No Neo4j to run. |
Self-hosted (Bolt) |
Python 3.10+. Neo4j 5.20+ (Aura, Desktop, or Docker — APOC plugin recommended). Optional OpenAI/Anthropic/Bedrock/Vertex key for client-side embeddings and LLM extraction. |